- Tue 12 December 2017
- Nilaksh Das
The field of machine learning has witnessed tremendous success in the recent years across multiple domains. It is not uncommon to witness the state of the art being challenged nearly every month, more so in the domain of computer vision. Many deep neural networks have been proposed that can beat even humans at certain tasks like image recognition.
However, it has recently been shown that even though these mathematical models appear to be so adept at natural tasks, the way they make certain decisions are extremely uninterpretable and somewhat precarious. For instance, given a model that does very well at the task of traffic sign recognition (e.g., a self-driving car would use something like this to make its decisions on the fly), the pixels of the input image that is consumed by the model can be changed so slightly that the change is completely invisible to humans, but confuses the model with embarrassing accuracy. Precise methods of constructing such input perturbations have been proposed in the recent literature that can target a fully observable model, but it’s adversarial effect transfers well even to other models which are not observed or targeted by the attack. This is especially the case with deep neural networks (DNNs), which lends researchers the reason to introspect how fragile DNNs really are in representing the input internally and how these models can be made more robust.
At the Intel Science and Technology Center for Adversary-Resilient Security Analytics (ISTC-ARSA), one of our many endeavors is to identify ways in which we can protect DNNs from such attacks. Part of my research here focuses on experimenting with preprocessing techniques that don’t require explicitly modifying the DNN architectures that work well. Instead, we focus on transforming the input to the network so as to preserve the original semantics and destroy any adversarial perturbations that may have been added to confuse the system. In this post, I will present empirical evidence that showcases the power of one such image preprocessing technique - JPEG compression - as a model agnostic defense to adversarial attacks.
State-of-the-Art Adversarial Attacks
Before we dive deeper into how JPEG compression works as a defense, let us take a look at some state-of-the-art adversarial attacks.
Fast Gradient Sign Method (FGSM)
Proposed by Goodfellow et al., the FGSM attack is one of the fastest ways of computing adversarial perturbations. This attack simply computes the sign of the gradient of the loss with respect to each pixel and scales it by a constant factor in the opposite direction. Put simply, it adds a constant magnitude perturbation to each pixel in an image; the sign of the perturbation corresponds to the direction which increases the overall classification loss.

DeepFool
Moosavi-Dezfooli et al. presented an optimal attack that efficiently computes the minimal perturbation for a given image that is enough to fool a model. It does so by linearizing the decision boundary of the model and iteratively perturbing the image so that it moves closer to the boundary, until it just crosses over. Since this attack computes the minimal perturbation required, it results in a very low magnitude of perturbation and is virtually invisible to the naked eye.
JPEG Compression as a Defense Against Adversarial Attacks
JPEG is a standard and widely-used image encoding and compression technique which mainly consists of the following steps:
-
converting the given image from RGB to YCbCr (chrominance + luminance) color space: this is done because the human visual system relies more on spatial content and acuity than it does on color for interpretation. Converting the color space isolates these components which are of more importance.
-
performing spatial subsampling of the chrominance channels in the YCbCr space: the human eye is much more sensitive to changes in luminance, and downsampling the chrominance information does not affect the human perception of the image very much.
-
transforming a blocked representation of the YCbCr spatial image data to a frequency domain representation using Discrete Cosine Transform (DCT): this step allows the JPEG algorithm to further compress the image data as outlined in the next step by computing DCT coefficients.
-
performing quantization of the blocked frequency domain data according to a user-defined quality factor: this is where the JPEG algorithm achieves the majority of the compression, at the expense of image quality. This step suppresses higher frequencies more since these coefficients contribute less to the human perception of the image.
The core principle motivating JPEG compression is based on the human psychovisual system. It aims to suppress high frequency information like sharp transitions in intensity and color hue using Discrete Cosine Transform. As adversarial attacks often introduce perturbations that are not compatible with human psychovisual awareness (hence these attacks are mostly imperceptible to humans), we hypothesize that JPEG compression has the potential to remove such perturbations.

Thus, we propose to use JPEG compression as a preprocessing step in the classification pipeline and experiment with varying the compression quality to see its effect on the misclassification success of adversarial attacks. Moreover, since applying JPEG compression might introduce artifacts of its own during classification, we also propose to vaccinate a DNN by retraining it on JPEG compressed images of a particular quality. A model is retrained multiple times on multiple qualities, and we use an ensemble of these models to get the final classification label. We tested our ensemble on the CIFAR-10 and GTSRB (German Traffic Sign Recognition Benchmark) datasets and present the results in the next section.
Results
The misclassification success of an adversarial attack is defined as the proportion of instances whose labels were successfully flipped by the attack, amongst all the instances which were correctly classified by the model.
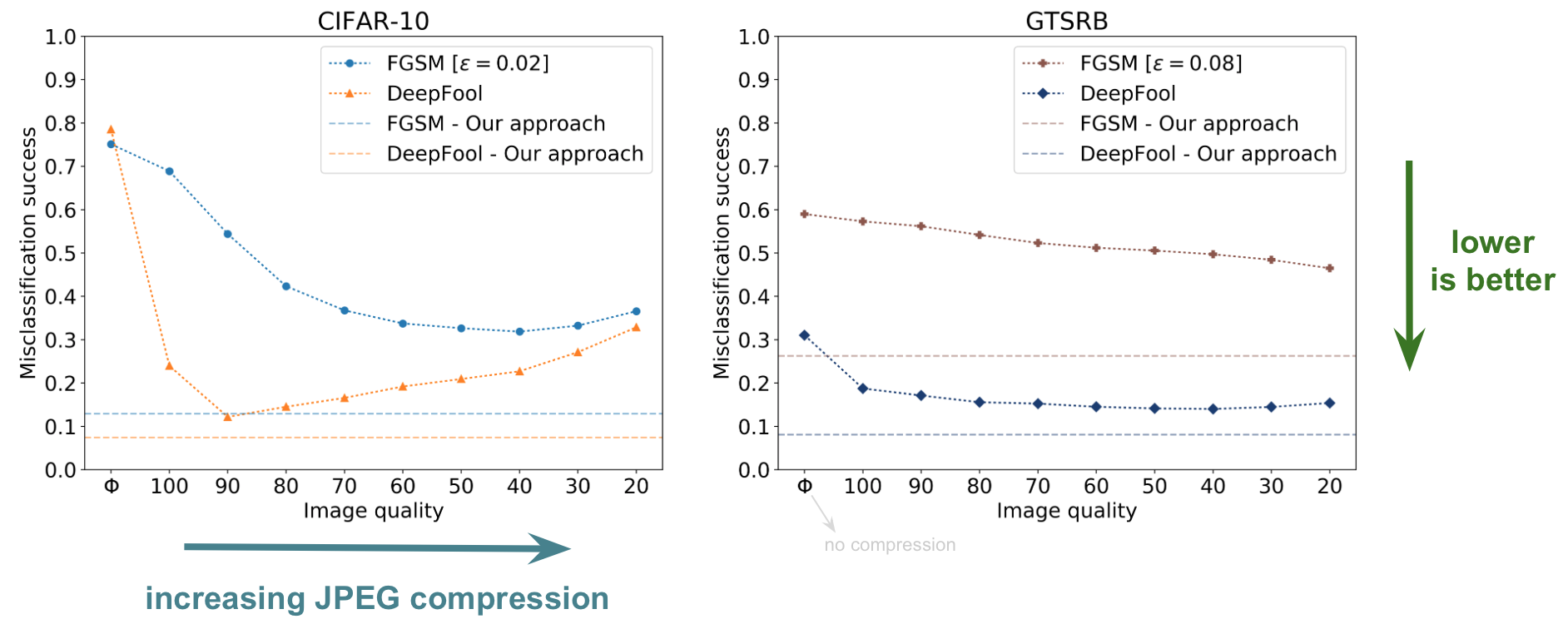
We see that varying the image quality of JPEG compression on the CIFAR-10 and GTSRB datasets reduces the misclassification success of FGSM and DeepFool attacks. The horizontal dashed lines show further drop in misclassification success using our ensemble of vaccinated DNNs.
Table 1: Classification accuracies with our approach on the respective test sets when original, non-vaccinated model is under attack.
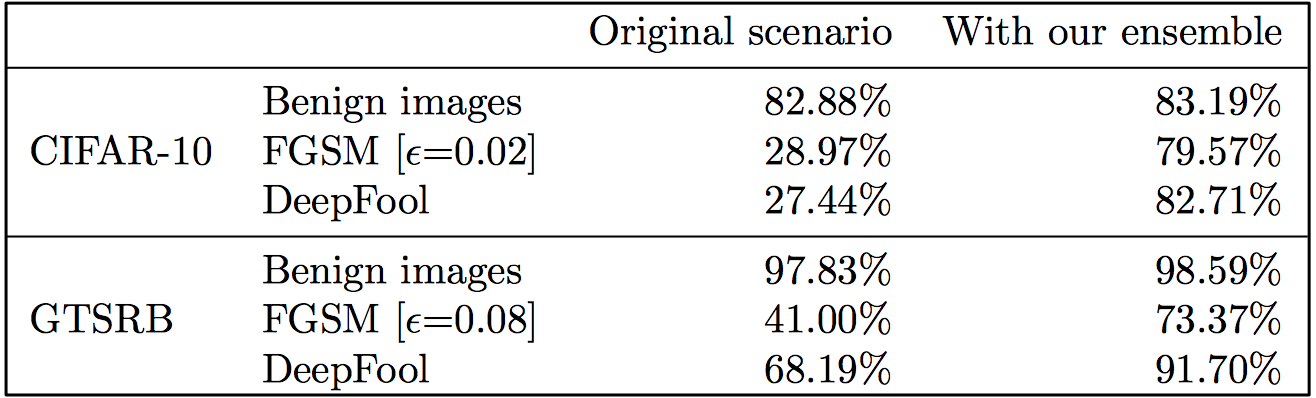
To summarize, we see that we are able to recover the classification accuracy significantly using our ensemble of vaccinated models under attack, and that the accuracy actually increases with benign images!
Discussion
Benign, everyday images lie in a very constrained subspace. An image with completely random pixel colors is highly unlikely to be perceived as natural by human beings. However, the objective basis of classification models like DNNs often is not aligned with such considerations. DNNs may be viewed as constructing decision boundaries that linearly separate the data in high dimensional spaces. In doing so, these models assume that the subspaces of natural images exist beyond the actual subspace. Adversarial attacks take advantage of this by perturbing images just enough so that they cross over the decision boundary of the model. However, this crossing over does not guarantee that the perturbed images would lie in the original narrow subspace. Indeed, perturbed images could lie in artificially expanded subspaces where natural images would not be found.
Since JPEG compression takes the human psychovisual system into account, we believe that the subspace in which JPEG images occur would have some semblance with the subspace of naturally occurring images, and that using JPEG compression as a preprocessing step during classification would re-project any adversarially perturbed instances back onto this subspace.
To gain further insights on this approach and for more details on our experiments, you can refer to our full paper found here.